


Νέες πληροφορίες για τους επερχόμενους επεξεργαστές με το κωδικό όνομα «Meteor Lake» και τη μονάδα επιτάχυνσης Τεχνητής Νοημοσύνης (VPU) που ενσωματώνουν έδωσε στη δημοσιότητα η Intel ενόψει της έκθεσης Computex 2023.
Οι επεξεργαστές Meteor Lake που θα λανσαριστούν μέχρι το τέλος του έτους θα είναι οι πρώτοι της Intel που θα περιλαμβάνουν στη συσκευασία τους μικτό σχεδιασμό με chiplets/tiles που θα κατασκευάζονται τόσο από την Intel όσο και από την TSMC. Οι συγκεκριμένοι επεξεργαστές θα διατεθούν πρώτα σε φορητούς υπολογιστές με την Intel να εστιάζει στην ενεργειακή αποδοτικότητα και στην υψηλή απόδοση σε φόρτους εργασίας τεχνητής νοημοσύνης σε τοπικό επίπεδο και λίγο αργότερα θα διατεθούν και για επιτραπέζιους υπολογιστές (desktop).
Τόσο η Apple όσο και η AMD έχουν ήδη προχωρήσει στην παρουσίαση επεξεργαστών με ενσωματωμένες μονάδες επιτάχυνσης τεχνητής νοημοσύνης ενώ και η Microsoft βρίσκεται επί του παρόντος απασχολημένη με την βελτιστοποίηση του λειτουργικού συστήματος Windows ώστε να αξιοποιεί τις διάφορες προσαρμοσμένες (custom-made) μηχανές επιτάχυνσης AI.

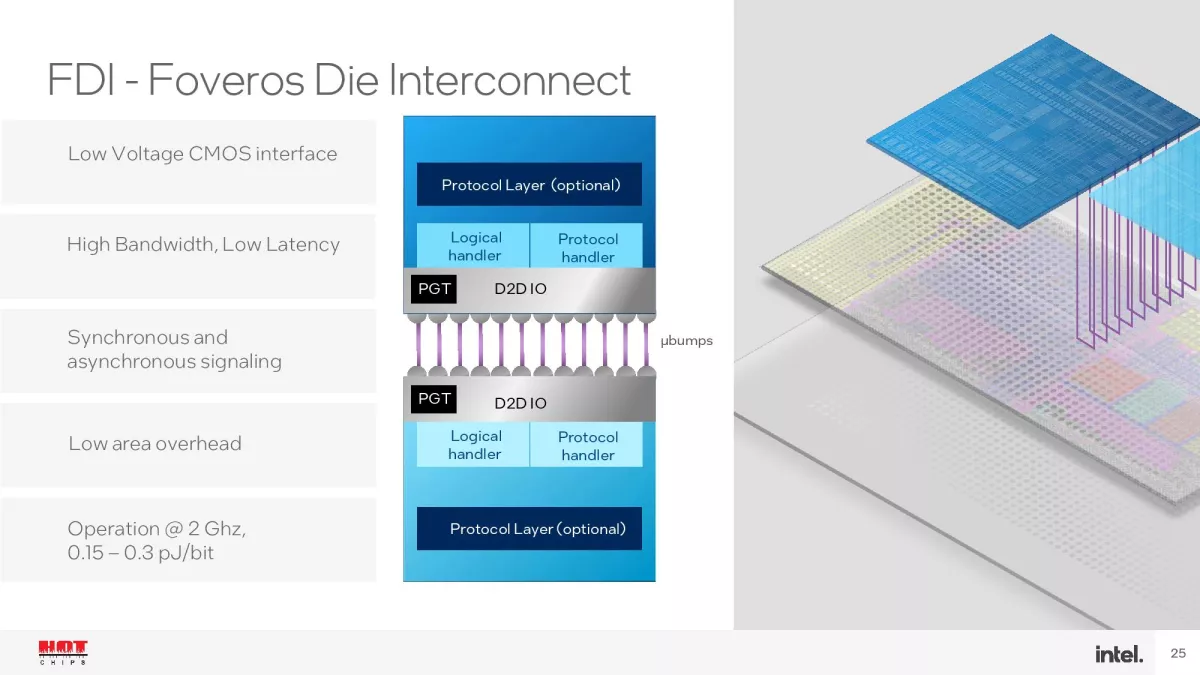
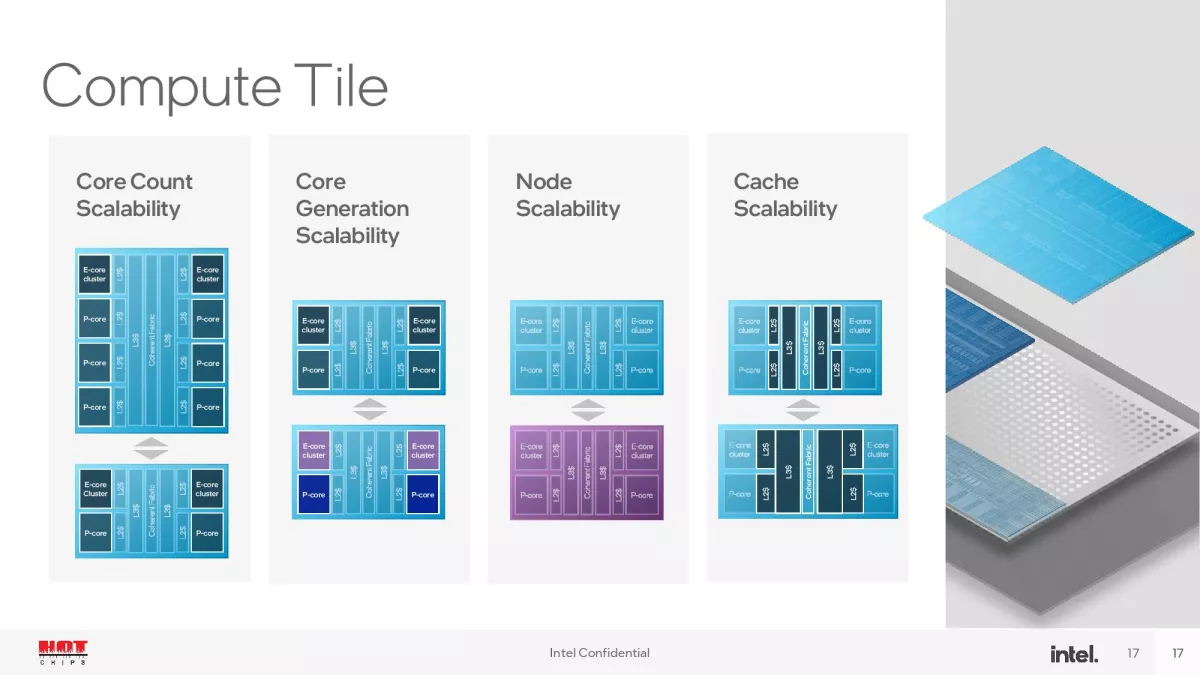
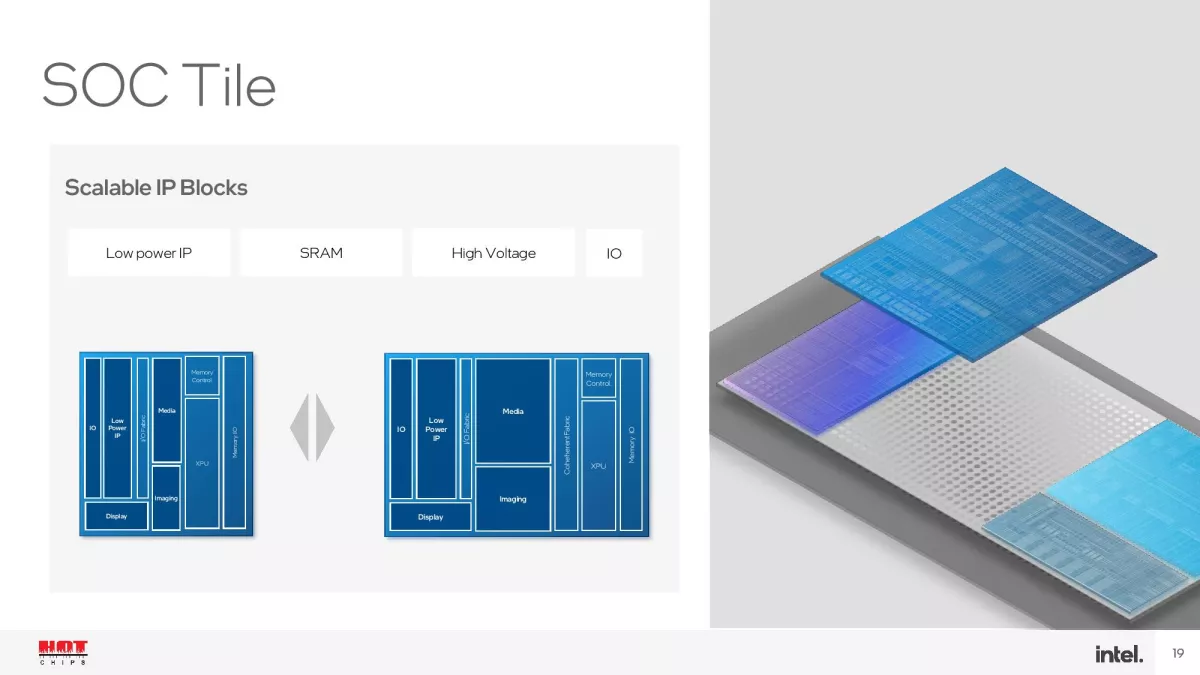
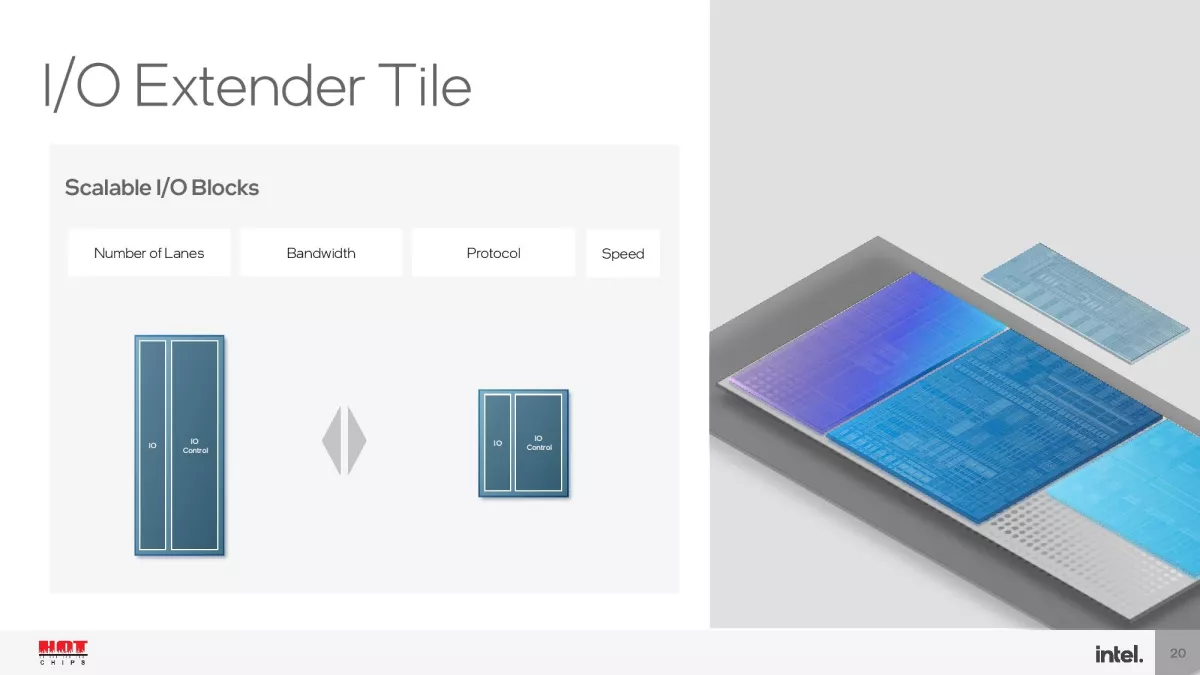
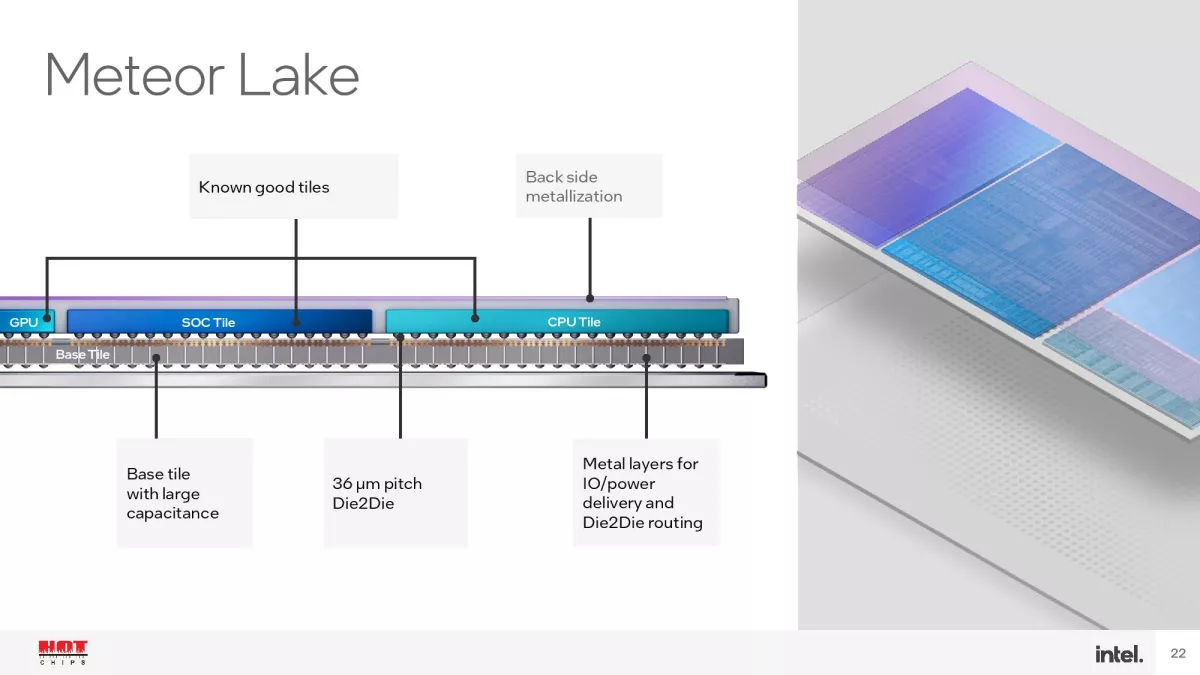
Οι 14ης γενιάς επεξεργαστές Intel Core με το κωδικό όνομα Meteor Lake θα βασίζονται σε σχεδιασμό με chiplets, χρησιμοποιώντας την κατασκευαστική μέθοδο Intel 4 και τις κατασκευαστικές μεθόδους N5 και N6 της TSMC. Χρησιμοποιώντας την τεχνική συσκευασίας/διασύνδεσης Foveros Die Interconnect της Intel, οι συγκεκριμένοι επεξεργαστές θα περιλαμβάνουν τέσσερις μονάδες/chiplets, τις CPU, GPU, SoC/VPU και I/O πάνω από μία ενδιάμεση διεπαφή (interposer). Το SoC/VPU δεν περιορίζεται μόνο στην επιτάχυνση εφαρμογών Τεχνητής Νοημοσύνης καθώς περιλαμβάνει και άλλο hardware -για άλλες λειτουργίες- όπως I/O Extender, Memory Controller, μονάδες επιτάχυνσης/πυρήνες GNA (Gaussian Neural Acceleration) και VPU κ.ά. Το συγκεκριμένο chiplet/tile θα κατασκευάζεται με τη μέθοδο N6 της TSMC.
Αν και βεβαίως θα χρειαστεί χρόνος ωσότου οι developers αξιοποιήσουν πλήρως τις μονάδες VPU στους επεξεργαστές της Intel, εντούτοις η εταιρεία υπολογίζει στην ανάπτυξη ενός οικοσυστήματος εφαρμογών AI στους προσωπικούς υπολογιστές. Η εταιρεία υποστηρίζει ότι έχει σημαντική παρουσία και εύρος στην αγορά για να φέρει την επιτάχυνση της Τεχνητής Νοημοσύνης στο «mainstream» και επισημαίνει τη συλλογική προσπάθεια που έφερε την υποστήριξη στους υβριδικούς επεξεργαστές x86 με τις ονομασίες «Alder Lake» και «Raptor Lake» στα Windows, στο Linux και στο ευρύτερο οικοσύστημα ISV.
Η επιτάχυνση AI σε σύγχρονα λειτουργικά συστήματα και εφαρμογές θα αποτελέσει αναμφισβήτητα πρόκληση για τη βιομηχανία γενικότερα. Η δυνατότητα εκτέλεσης φόρτων εργασίας AI σε τοπικό επίπεδο δεν θα αξίζει και πολλά αν για παράδειγμα οι developers διαπιστώσουν ότι είναι δύσκολο να αναπτύξουν εφαρμογές (π.χ. επειδή κάθε κατασκευαστής χρησιμοποιεί δικό του ιδιόκτητο σύστημα και hardware για την επιτάχυνση AI).
Θα πρέπει να υπάρξει ένας κοινός διασυνδετικός κρίκος για την υποστήριξη φόρτων εργασίας ΑΙ σε τοπικό επίπεδο και σε αυτό το σημείο, οι βιβλιοθήκες επιτάχυνσης DirectML DirectX 12 για μηχανική εκμάθηση -μία προσέγγιση που υποστηρίζεται από τος Microsoft και AMD- θα παίξουν σημαντικό ρόλο.

Το VPU της Intel υποστηρίζει DirectML καθώς και ONNX και OpenVINO, που θα προσφέρουν υψηλότερη απόδοση στους δικούς της επεξεργαστές (με τους developers να χρειάζεται να αναπτύξουν το λογισμικό τους ειδικά για αυτά τα πρότυπα αν θέλουν να εξαγάγουν τη μέγιστη απόδοση).
Πολλοί από τους σημερινούς, περισσότερο απαιτητικούς φόρτους εργασίας AI, όπως είναι τα μεγάλη γλωσσικά μοντέλα όπως το ChatGPT απαιτούν πολύ μεγάλη επεξεργαστική ισχύ και για αυτό θα εξακολουθήσουν να λειτουργούν σε μεγάλα κέντρα δεδομένων.
Παρόλα αυτά, η Intel εκφράζει ανησυχίες για το απόρρητο το δεδομένων ή κάνει λόγο για υστέρηση -στην εξαγωγή αποτελεσμάτων- και υποστηρίζει ότι αρκετές εργασίες και εφαρμογές που σχετίζονται με τη Τεχνητή Νοημοσύνη θα μπορούσαν να πραγματοποιούνται τοπικά, όπως η επεξεργασία ήχου, βίντεο και εικόνας (π.χ. με τη μηχανή γραφικών Unreal Engine). INSOMNIAGR


0 Post a Comment:
إرسال تعليق