


Η εταιρία δείχνει με ποιον τρόπο η τωρινή σχεδίαση των chiplets συνεισφέρει στις χαμηλές τιμές αναλογικά με τον ανταγωνισμό.
Οι δύο μεγάλες εταιρίες στον χώρο των επεξεργαστών Intel και AMD βρίσκονται αρκετά κοντά από άποψης επιδόσεων στις περισσότερες εφαρμογές όμως χρησιμοποιούν πολύ διαφορετική σχεδίαση στα chip τους και η AMD αναφέρει σε σχετική παρουσίαση τα οφέλη της δικής της. Στο φετινό Solid-State Circuits Conference η AMD κάνει έναν υπολογισμό του κόστους ενός σύγχρονου Ryzen επεξεργαστή τρίτης γενιάς ο οποίος ενσωματώνει ξεχωριστά chiplets για το I/O και ξεχωριστά για τις ομάδες των πυρήνων της, μια σχεδίαση που είχαμε μελετήσει αρκετά στη πρώτη μας επαφή με τη πλατφόρμα.
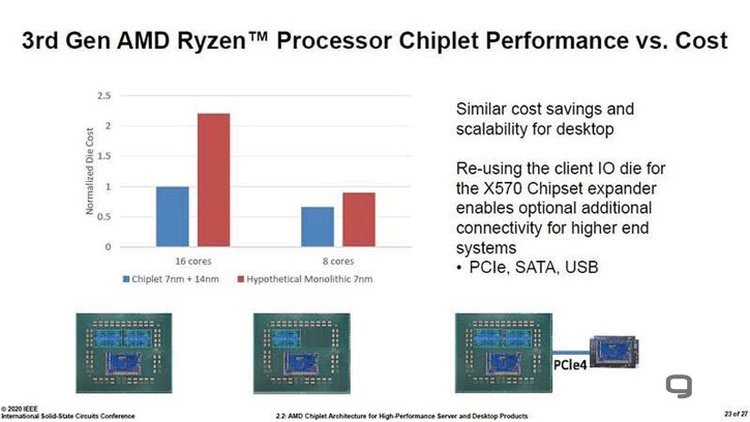 Αντίθετα η Intel ενσωματώνει σε όλες τις πρόσφατες γενιές επεξεργαστών, τόσο στη mainstream όσο και στο high end desktop τη μονολιθική σχεδίαση που σημαίνει πως οι επεξεργαστές της αποτελούνται από ενιαία κομμάτια πυριτίου ενσωματώνοντας εκεί όλα τα απαραίτητα υποσυστήματα όπως έξτρα ελεγκτές PCIe μεταξύ άλλων, μια μέθοδος κατασκευής που με τη σειρά της καταλαμβάνει αρκετό χώρο από το εκάστοτε wafer - και για αυτόν (μεταξύ άλλων) τον λόγο θεωρείται γενικά ακριβή. Σημειώνεται ότι στο I/O die των AMD βέβαια βρίσκουμε και άλλα υποσυστήματα όπως SATA και USB controllers τα οποία καταλαμβάνουν χώρο και δεν υπάρχουν στους επεξεργαστές της Intel στη mainstream και την HEDT αγορά.
Αντίθετα η Intel ενσωματώνει σε όλες τις πρόσφατες γενιές επεξεργαστών, τόσο στη mainstream όσο και στο high end desktop τη μονολιθική σχεδίαση που σημαίνει πως οι επεξεργαστές της αποτελούνται από ενιαία κομμάτια πυριτίου ενσωματώνοντας εκεί όλα τα απαραίτητα υποσυστήματα όπως έξτρα ελεγκτές PCIe μεταξύ άλλων, μια μέθοδος κατασκευής που με τη σειρά της καταλαμβάνει αρκετό χώρο από το εκάστοτε wafer - και για αυτόν (μεταξύ άλλων) τον λόγο θεωρείται γενικά ακριβή. Σημειώνεται ότι στο I/O die των AMD βέβαια βρίσκουμε και άλλα υποσυστήματα όπως SATA και USB controllers τα οποία καταλαμβάνουν χώρο και δεν υπάρχουν στους επεξεργαστές της Intel στη mainstream και την HEDT αγορά.
Εάν οι Ryzen κατασκευάζονταν με βάση τη μονολιθική σχεδίαση της Intel τα πράγματα θα ήταν πολύ διαφορετικά, δηλώνει η εταιρία μέσα από μια σειρά slides που συγκρίνουν ένα μοντέλο οκτώ πυρήνων. Με το I/O και τους πυρήνες σε ένα στοιχείο το chip θα κόστιζε περίπου 50% περισσότερο ενώ εάν η σύγκριση περιλαμβάνει τον μεγάλο δεκαεξαπύρηνο Ryzen 9 3950X, τότε το κόστος του θα ήταν 125% μεγαλύτερο απ' ότι τώρα, επιβεβαιώνοντας έτσι και το κόστος των επεξεργαστών της Intel. Όπως όμως δείχνουν οι επιδόσεις η διαφορετική σχεδίαση δε παίζει μεγάλο ρόλο εκεί, αλλά περισσότερο στη τελική τιμή και τα όποια μειονεκτήματα του latency στην επικοινωνία με το γειτονικό die δείχνουν να οριοθετούνται με τη χρήση αρκετής τοπικής cache δίπλα στους πυρήνες.


0 Post a Comment:
إرسال تعليق